Most organizations do not suffer from a lack of data. They suffer from a lack of shared structure.
Sales teams track customers one way. Operations teams manage fulfillment another way. Finance uses its own identifiers. Support teams create records around tickets, cases, and exceptions. Leadership receives summaries that often depend on manually reconciled spreadsheets, exported reports, and institutional memory. The result is not simply fragmented data. It is fragmented operational truth.
Agentic database normalization introduces a different approach. Instead of relying only on rigid migration scripts, manual cleanup, or one-time integrations, agentic systems can help identify entities, map fields, resolve inconsistencies, enrich records, and preserve the reasoning behind normalization decisions.
Key findings
Failure point
Disparate systems
Business functions often define customers, projects, vendors, assets, and transactions differently.
Operational cost
Manual reconciliation
Teams recreate the same truth through spreadsheets, exports, status meetings, and one-off cleanup.
Most effective control
Agentic normalization layer
A governed AI-assisted layer can reconcile records while keeping humans in control of approval and governance.
The core problem: every department creates its own version of reality
Disjointed systems are not always a technology failure. They are often the natural result of business growth. A company adds a CRM, then project management, then finance tools, spreadsheets, support systems, document repositories, and internal applications. Each solves a real local problem. Over time, each becomes a partial source of truth.
Questions that become difficult to answer
- Which customer record is the correct one?
- Has this vendor already been approved?
- Which project status is current?
- Which document belongs to which transaction?
- Which system should leadership trust?
What agentic database normalization means
Agentic database normalization is the use of AI-driven agents to assist with transforming fragmented, inconsistent, and duplicated data into structured, reliable, and interoperable records. This does not mean letting AI freely rewrite company data. The agent assists with interpretation, comparison, and transformation, while system owners define schema, approval rules, fallback paths, and governance.
Responsible normalization sequence
- 01
Ingest records from multiple systems
Collect records from business systems, uploads, APIs, spreadsheets, and documents while preserving source context.
- 02
Identify entities across different formats
Recognize likely customers, vendors, projects, employees, invoices, assets, or transactions across inconsistent records.
- 03
Detect duplicates and conflicts
Flag naming inconsistencies, missing fields, and competing identifiers before records are merged.
- 04
Map fields into a shared schema
Translate local system fields into canonical business fields that support operations and reporting.
- 05
Suggest normalized records
Generate proposed normalized outputs instead of silently rewriting source truth.
- 06
Flag uncertain matches for review
Low-confidence or high-impact changes should move into review instead of automatic merge.
- 07
Preserve decision history
Keep reasoning, change logs, and reviewer decisions visible for trust and auditability.
- 08
Write approved records into the operational layer
Publish approved normalized records into the structured data layer that powers reporting, tooling, AI retrieval, and workflows.
Why integration alone is not enough
Traditional integration focuses on moving data from one system to another. That is useful, but it does not automatically solve meaning. One tool may treat a company as a customer, another as a billing account, and another as a project sponsor. Moving all of that data into one place without normalization can simply centralize the confusion.
The normalization layer
A governed normalization architecture
- 01
Source systems
CRMs, ERPs, spreadsheets, databases, ticketing tools, finance systems, documents, and internal applications remain the sources of raw operational signals.
- 02
Agentic processing layer
This layer performs entity recognition, field mapping, duplicate detection, schema alignment, conflict identification, enrichment, and confidence scoring.
- 03
Human review layer
Uncertain records, high-impact changes, and conflicting interpretations move through review workflows before they affect production truth.
- 04
Normalized data layer
Approved records are stored in structured form to support dashboards, internal tools, reporting, AI retrieval, workflow automation, and decision systems.
- 05
Operational interface
The business sees value only when teams can ask clear questions and receive trusted answers across business functions.
Where fragmentation appears first
- Customer and account records — The same customer may exist across sales, finance, support, and delivery systems with different names, contacts, addresses, and identifiers.
- Project and workflow status — Teams may use different status labels, making it difficult to understand whether work is planned, active, blocked, completed, invoiced, or archived.
- Vendor and partner data — Vendor records often become duplicated across procurement, finance, legal, and operations.
- Documents and attachments — Contracts, invoices, forms, reports, and correspondence may not be reliably connected to the correct operational record.
- Reporting and leadership visibility — Executives often receive information that has already passed through several manual transformations, making the source of truth difficult to trace.
Agentic normalization workflow
Practical workflow stages
- 01
1. Data intake
Collect records from business systems, uploads, APIs, spreadsheets, and documents while preserving source, timestamp, owner, and system context.
- 02
2. Entity detection
Identify likely customers, vendors, projects, employees, invoices, assets, locations, or transactions.
- 03
3. Schema mapping
Map fields from different systems into a shared data model.
- 04
4. Similarity matching
Compare records that may refer to the same entity using names, emails, addresses, IDs, document references, transactions, and contextual clues.
- 05
5. Conflict detection
Flag mismatched values, missing fields, competing identifiers, and records that cannot be confidently merged.
- 06
6. Confidence scoring
Assign confidence to each suggested normalization action so low-confidence changes can be routed for review.
- 07
7. Human approval
A reviewer confirms, rejects, or edits suggested normalized records to preserve trust, accountability, and compliance.
- 08
8. Normalized record creation
Approved records are written into the structured data layer with traceability back to source records.
- 09
9. Continuous learning
Review outcomes reveal naming patterns, field relationships, and exception types that improve the system over time.
Shared schema mapping example
Normalization layer diagram
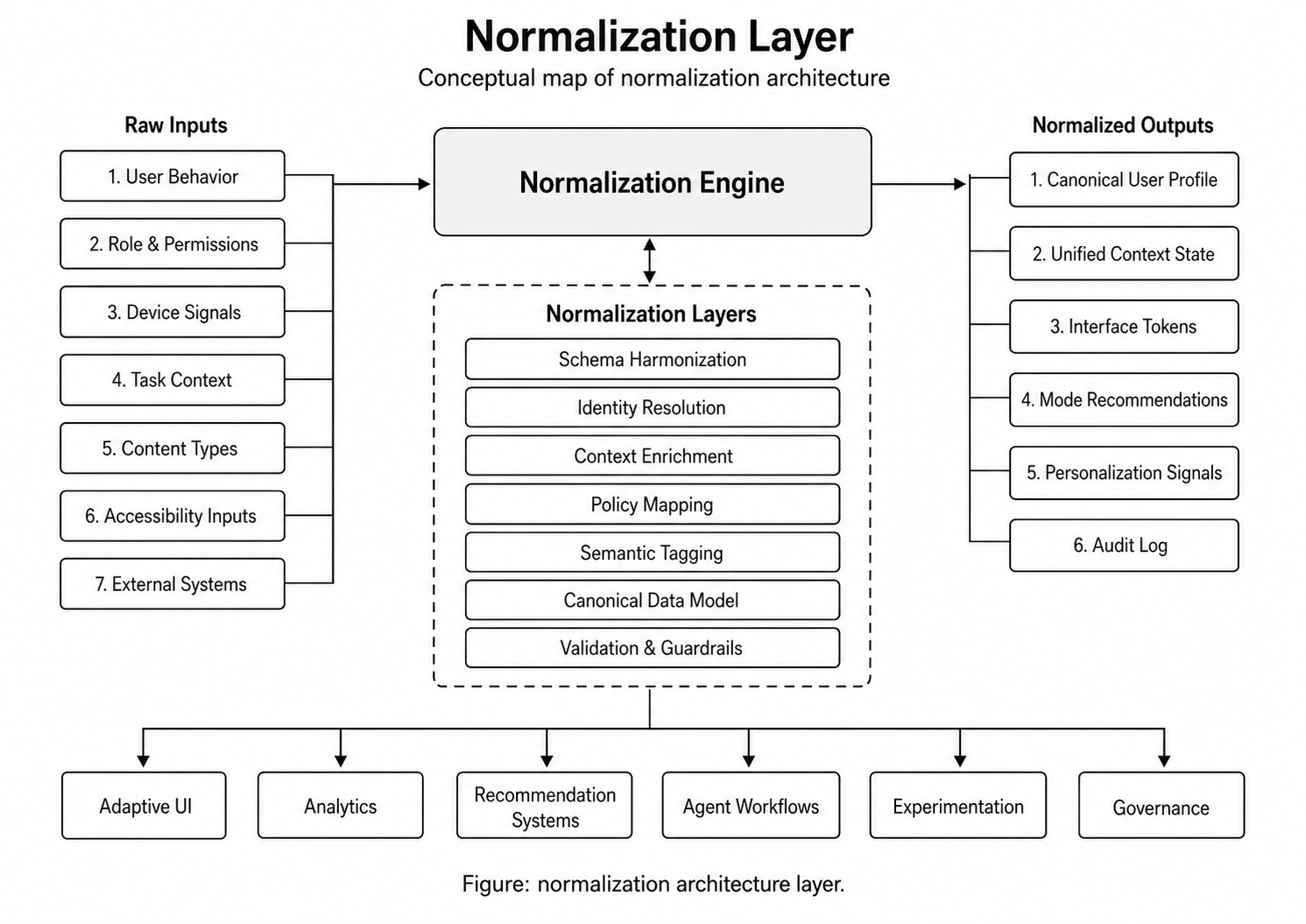
What this unlocks
- Unified customer view — Teams can see a more complete picture of each customer across sales, delivery, finance, and support.
- Cleaner reporting — Leadership can make decisions from normalized records instead of manually reconciled spreadsheets.
- Better AI retrieval — AI systems perform better when the underlying data is structured, deduplicated, and semantically consistent.
- Workflow automation — Automations become safer when they operate on reliable records with clear ownership and state.
- Faster system migration — Companies preparing to move from legacy tools to modern platforms can reduce migration risk.
- Improved operational trust — Teams spend less time debating which system is correct and more time acting on shared information.
Design requirements for responsible agentic normalization
- Source traceability — Every normalized record should link back to its original source records.
- Confidence thresholds — The system should distinguish between high-confidence matches and uncertain suggestions.
- Human review paths — Low-confidence or high-impact changes should require approval.
- Schema governance — The organization should define canonical fields, ownership rules, and acceptable transformations.
- Change history — Every merge, correction, field update, and reviewer action should be recorded.
- Rollback capability — Bad merges or incorrect transformations should be reversible.
- Business-language visibility — Users should understand what changed, why it changed, and which rule or source influenced the result.
Strategic implication
Agentic database normalization changes the role of AI in business operations. Instead of only generating text or automating isolated tasks, AI can help create the structured foundation that makes the rest of digital transformation possible. The most valuable AI systems will not simply sit on top of company data. They will help reshape the data layer itself into something coherent, observable, and operationally useful.
“The next phase of digital transformation is not only about connecting systems. It is about normalizing meaning across the business.”